Better answers.
Data that just works.
Integrated and governed.
CX AI: Solved
We help CX leaders turn fragmented data into a single AI knowledge layer for smarter automation, higher containment and experiences your live agents and customers can trust.





AI success in three simple steps
Step 1
Engineer your knowledge
“Inbenta AI’s Knowledge revolutionized our ability to organize, update, and access accurate data across the organization.”
Do you have a strong foundation in place?
AI success starts with the fundamentals. Inbenta’s knowledge engineering helps you simplify your stack,define clear goals, and scale AI with expert support.
Step 2
Launch value-driven AI solutions
“We’re glad to have Inbenta AI on our side. They helped us digitize and automate service ops to +1.5M users.”
Are your AI initiatives actually moving the needle?
Embed AI where it matters most. Inbenta AI delivers tailored, high-accuracy solutions that prioritize transparency, explainability, and real business value from day one.
Step 3
Measure & optimize performance
“With Inbenta AI, we received more positive user feedback than in thepast decade of other digital transformation efforts.”
Can you prove AI’s impact to continuously improve and scale?
Make AI accountable. Inbenta AI provides governance, real-time performance tracking, and compliancetools so you can measure impact, stay audit-ready, and continuously improve outcomes.
+90%
self-service rate
99%
response accuracy
+60%
reduction in service cost
“Inbenta AI’s knowledge revolutionized our ability to organize, update, and access accurate data across the organization.”
“We’re glad to have Inbenta AI on our side. They helped us digitize and automate service ops to +1.5M users.”
“With Inbenta AI, we received more positive user feedback than in thepast decade of other digital transformation efforts.”
INBENTA AI PLATFORM
A knowledge-first AI platform built for scale
Empower users with AI-driven solutions across channels and content mediums — including voice, video, live translation, and seamless agent escalation.

Inbenta AI
Our core capabilities in action
See how Inbenta powers real-world AI success across Customer Experience, Employee Experience, and operations.
CUSTOMER STORIES
A proven track record driving business value through AI












Why partner with Inbenta AI




Tailored solutions that accelerate your AI evolution
A fully integrated AI ecosystem with scalable automation, seamless integrations, omnichannel UX, and real-time advanced analytics.
Flexible, integrated platform
Automate workflows, execute tasks, and drive intelligent enterprise operations.
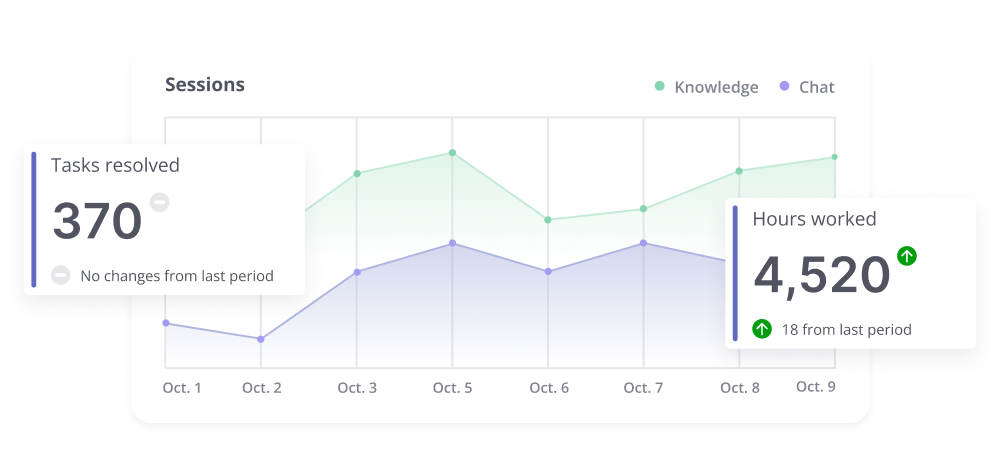
Real-time analytics
Extract insights to cut costs, boost satisfaction, and unlock growth opportunities.

Integrate your enterprise tools with AppHub — no rip-and-replace
Inbenta AI’s platform integrates all major AI models, data systems, CRMs, and other enterprise tools.
Composite AI
Combine Conversational AI’s structure with GenAI’s creativity for dynamic, precise interactions.
Voice. Video. Translation.
Engage in human-like voice and video interactions with live translation for a unified conversational experience.
Live translation
Inbenta AI breaks down language barriers for a localized, personalized experience globally.
Get started with Inbenta AI today
AI that adapts to your needs from a partner you can trust.
